OpenAI and Anthropic Face Off
OpenAI and Anthropic are in direct competition once again.
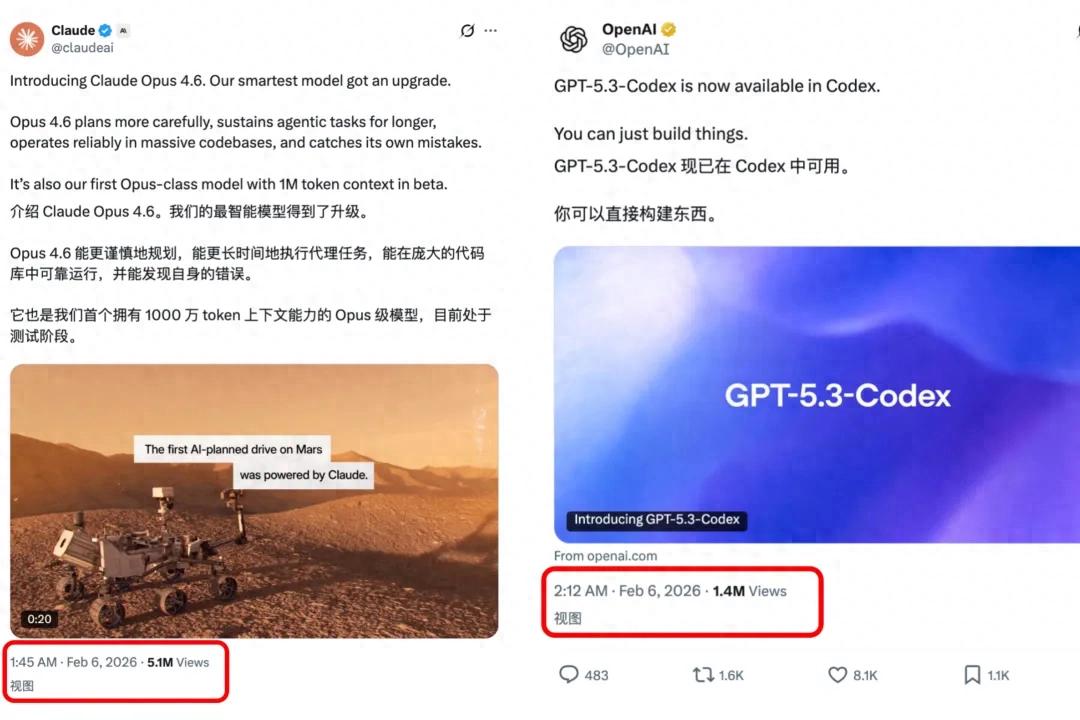
Claude Opus 4.6 was released less than half an hour before GPT-5.3-Codex went live, without any prior announcements or buildup.
This is not just a minor update; it represents OpenAI’s most powerful agent-based programming model to date.
Interestingly, OpenAI has acknowledged that the Codex team utilized early versions during the development of GPT-5.3 to debug training, manage deployments, diagnose test results, and evaluate performance—essentially, AI participated in its own development.
While previous versions of Codex acted primarily as efficient coding assistants, GPT-5.3-Codex is a general agent capable of performing nearly all professional tasks on a computer.
How versatile is it? It not only writes code but can also run long-term tasks, call tools, operate terminals, and manage deployment processes. In other words, it can handle almost the entire development lifecycle from R&D to deployment.
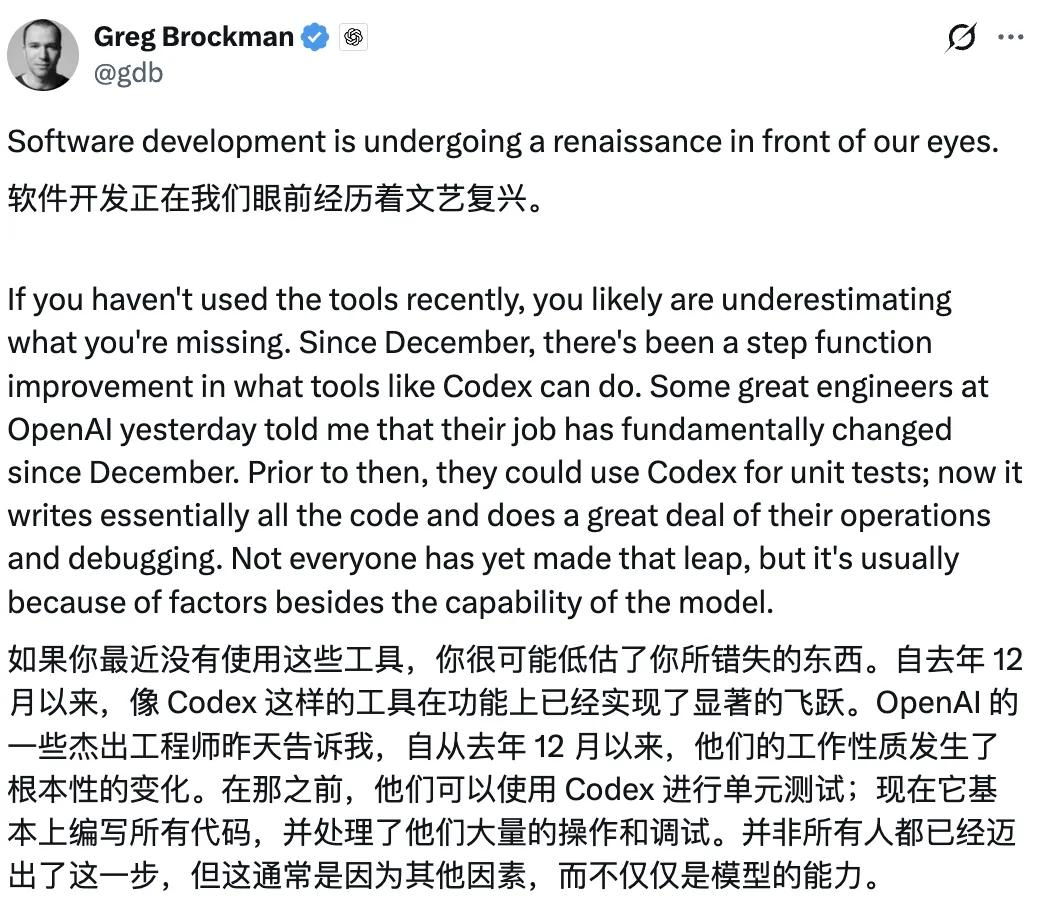
According to OpenAI co-founder and president Greg Brockman, software development is undergoing a renaissance, with agents becoming the ‘first interface’.
They have set an ambitious goal: for any technical task, the first human response should be to interact with an agent rather than open an editor or terminal.
Benchmark Performance
So, how effective is GPT-5.3-Codex? Let’s look at the benchmark scores for a clear perspective.
The most notable change is its enhanced execution capability in terminal environments. In Terminal-Bench 2.0, GPT-5.3-Codex scored 77.3%, nearly a 13 percentage point increase over GPT-5.2-Codex.
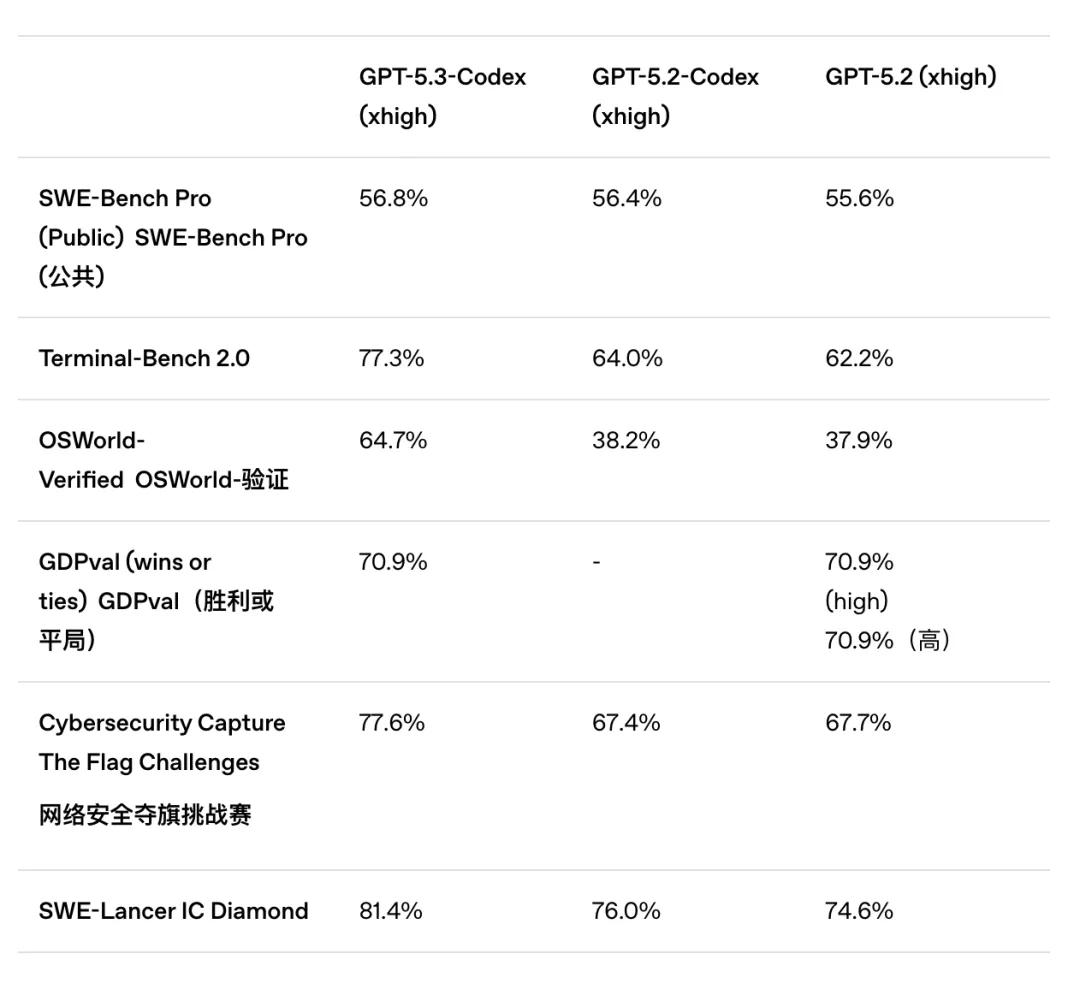
Terminal-Bench 2.0 measures not just whether the model can write code but its ability to complete real engineering tasks in a terminal environment: executing commands, utilizing tools, performing multi-step processes, and debugging errors.
In other words, this metric assesses performance in real-world engineering contexts, unlike SWE-Bench, which focuses on isolated problem-solving.
Interestingly, Claude Opus 4.6 also participated in Terminal-Bench 2.0, scoring 65.4%, meaning GPT-5.3-Codex outperformed it by 12%.
Additionally, GPT-5.3-Codex shows improvements in several areas:
- Doubling computer operation capabilities. It scored 64.7% in OSWorld, compared to 38.2% for the previous GPT-5.2-Codex.
- In terms of cybersecurity capabilities, it scored 77.6% in Cybersecurity CTF, an improvement of about 10% over GPT-5.2-Codex.
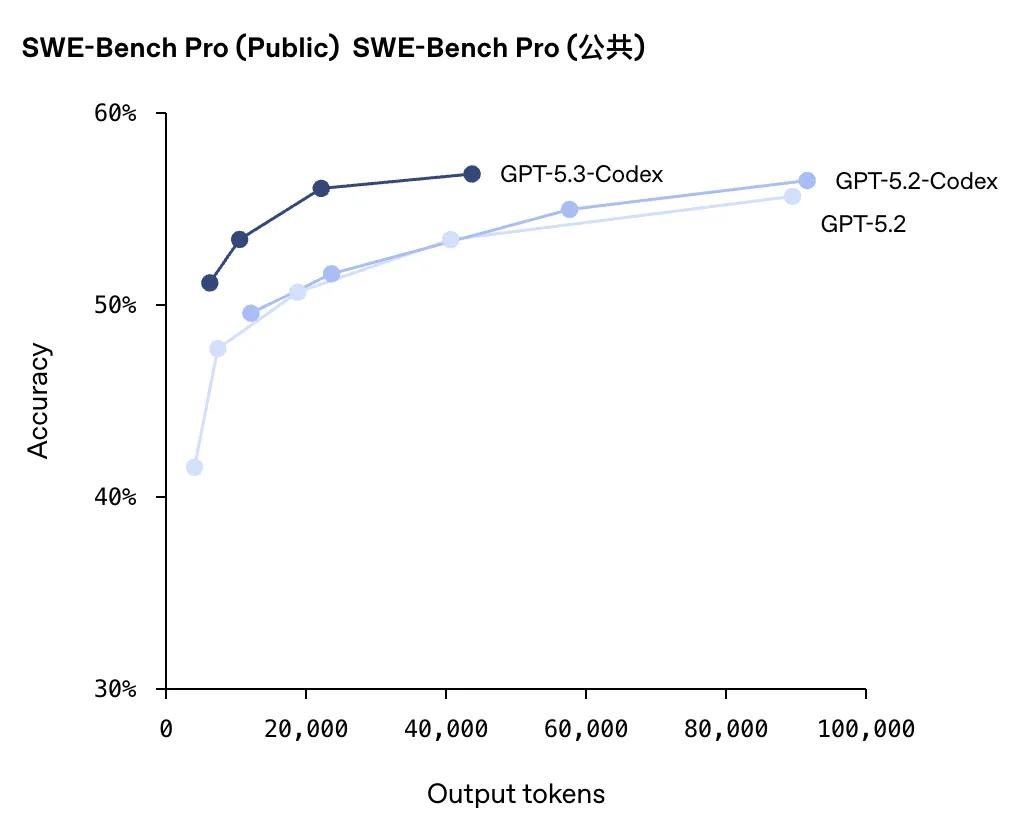
- Regarding output accuracy, GPT-5.3-Codex consistently outperforms GPT-5.2-Codex across various output token counts.
User Experiences
When asked whether GPT-5.3-Codex or Claude Code is more effective, user Gork humorously responded:
A user named Matt Shumer, who is also the creator of GitHub for prompts, quickly tested GPT-5.3-Codex and seemed quite satisfied with the results. He even titled his blog post: ‘The Era of Complete Autonomy Has Arrived’.
In his blog, he excitedly wrote that this was the first time he felt confident enough to delegate a task to the model and walk away for several hours (even over 8 hours) without it crashing, drifting, or losing intelligence.

Matt noted that GPT-5.3-Codex not only writes code but also fills in vague information, makes architectural decisions, fixes bugs, deploys, and monitors logs, iterating until tests pass. As long as clear validation criteria are provided, it can run for hours without deviation.
What delighted him most was not just the model’s ‘intelligence’ but its judgment: when instructions were ambiguous, the path chosen by the AI often aligned with what he would have chosen, rather than opting for a seemingly quicker but potentially problematic ‘shortcut’.
As long as pass/fail criteria are clearly defined, it can iterate and refine until all tests pass. The clearer the criteria for determining correctness, the better it can self-correct without constant human intervention.
Moreover, it can complete the entire feedback loop: modifying code, pushing changes, deploying, opening online links, and tailing logs—continuing to fix issues until everything works.
Matt provided an example where he granted the model permissions for a deployment tool like Railway CLI, allowing it to complete the ‘go live’ step and then make adjustments based on online feedback until it was fully functional.
Additionally, GPT-5.3-Codex effectively utilizes wait times: while commands are executing, it can update documentation, provide context, and address minor issues without altering unrelated areas.
In essence, this model resolves the ‘heartburn’ experienced when multiple agents are used for Vibe Coding: it understands boundaries well, performing helpful tasks without overstepping or making unnecessary changes.
Matt pointed out that in terms of long-chain task stability, GPT-5.3-Codex clearly outperforms Opus 4.5. Although it may be slower than Opus 4.5, it is also more stable.
Furthermore, multiple agents no longer resemble mere chat performances: Matt believes GPT-5.3-Codex can genuinely divide tasks into several parallel workflows, with each agent focusing on a specific area, leading to faster overall progress and reducing the likelihood of oversight.
However, the drawbacks of GPT-5.3-Codex, or the costs paid for stability, are evident: it is indeed slower. Additionally, process reporting may occasionally drop, making it less suitable for designing prompt/agent architectures.
But if your priority is to ‘avoid errors, stay on track, and not require constant oversight’, it finally feels like a viable solution. More precisely, it may not be the ‘most entertaining’ model, but for tasks that are complex, long-term, constrained, and require precision, it provides enough reassurance to users.
OpenAI’s Vision for Software Development
As mentioned earlier, OpenAI co-founder and president Greg Brockman posted about the ongoing ‘renaissance’ in software development, with agents becoming the ‘first interface’ for engineers.
He believes that models like GPT-5.3-Codex are now powerful enough to independently manage an entire engineering workflow under complex constraints over extended periods: from coding to debugging, deployment, and continuous iteration.
When a model’s capabilities reach this level, the question shifts from ‘should we use it?’ to whether companies are ready to overhaul their processes, code structures, and even team collaboration methods.
This post serves as an internal transformation guideline, discussing not only the model’s enhanced capabilities but also how engineering organizations should adapt when the default interface becomes an agent. The full content is as follows:
Software development is undergoing a renaissance right before our eyes.
If you haven’t been using these tools recently, you may be underestimating what you’ve missed. Since last December, tools like Codex have seen a leap in capabilities.
Several outstanding engineers at OpenAI have informed me that their working methods have fundamentally changed since December. Previously, they could only use Codex to write unit tests; now, it writes almost all code and takes on significant operational and debugging tasks. Not everyone has made this transition, but the obstacles they face are generally not due to the model’s capabilities.
Now, every company faces the same opportunity. To harness it, just as with cloud computing or the internet in the past, careful consideration is required. This article shares how OpenAI is currently restructuring its teams for ‘agent-based software development’. We are still learning and iterating, but this is our current thinking:
- For any technical task, the first tool choice for humans should be to interact with the agent, rather than opening an editor or terminal.
- The way humans default to using agents must undergo clear safety assessments while being efficient enough that most workflows require no additional approval.
To achieve this goal, we proposed the following suggestions to the team a few weeks ago:
- Spend time genuinely trying these tools. Many have had amazing experiences with Codex 5.2, but some have not yet tried it due to busyness or doubts about ‘can it really do X?’ instead of just giving it a shot.
- Designate an ‘Agent Lead’ for the team, specifically to think about how to integrate agents into team workflows.
- Share experiences and issues through internal channels.
- Host a company-wide Codex Hackathon.
- Create skills and AGENTS.md files.
- Maintain an AGENTS.md for each project, updating it promptly when the agent encounters errors or gets stuck.
- Abstract the capabilities you have Codex execute as skills and submit them to a shared repository.
- Inventory and open internal tools.
- List the tools the team relies on and ensure someone is responsible for making them accessible to agents (e.g., providing CLI or MCP Server interfaces).
- Structure code repositories with ‘Agent First’ in mind.
- Write fast-running tests.
- Build high-quality component interfaces.
- Reject ‘garbage code’.
- Managing AI-generated code at scale presents a new challenge that requires new processes and standards.
- Ensure every merged code segment has a clear human owner.
- Review standards must be at least as strict as those for human-written code.
- Build infrastructure.
- Not only should the final submitted code be recorded, but also the execution traces of the agent.
- Establish observability systems and unified tool management mechanisms.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.